Example of a suboptimal packfile
I think I’ve managed to come up with a self-contained example where git’s heuristic doesn’t make the optimal packfile.
We’ve got the following files:
Each file consists of 2048 lines of random text. Each line consists of 512 chars (including newline). So each file is 1 MB.
I’ve randomly replaced 100 lines in files with random chars following a particular scheme. Each file has one parent (except a.txt) and 100 of the lines of the parent have been replaced to create the child. Here’s one visualization.
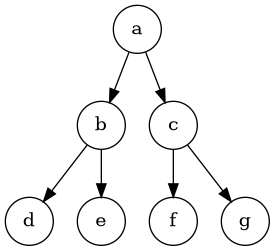
Another way of seeing this is looking at the count of lines that differ for all pairs of files:
| a.txt | b.txt | c.txt | d.txt | e.txt | f.txt | g.txt | |
|---|---|---|---|---|---|---|---|
| a.txt | 0 | 100 | 100 | 195 | 197 | 200 | 192 |
| b.txt | 100 | 0 | 195 | 100 | 100 | 292 | 284 |
| c.txt | 100 | 195 | 0 | 284 | 285 | 100 | 100 |
| d.txt | 195 | 100 | 284 | 0 | 194 | 380 | 369 |
| e.txt | 197 | 100 | 285 | 194 | 0 | 378 | 371 |
| f.txt | 200 | 292 | 100 | 380 | 378 | 0 | 197 |
| g.txt | 192 | 284 | 100 | 369 | 371 | 197 | 0 |
In theory you could make a packfile that has a.txt as the root object and then store b.txt and c.txt in terms of a.txt, d.txt and e.txt in terms of b.txt, and f.txt and g.txt in terms of c.txt.
Uncompressed size of the packfile should be a bit more than 1024KB + 6 * (100 * 512) = 1355776 (1324KB). (“Bit more” because of the overhead of the instructions.)
If you run git gc it gets close but it doesn’t get near the optimum:
159add8b7ff14a8c06802bada413b896073c3456d blob 1048576 667202 12
247649b95538818d51d1e926fe16b0950b7d34e75 blob 52161 33711 667214 1 59add8b7ff14a8c06802bada413b896073c3456d
3613c0f78b0ec58462d9d4cf3f4c81b118dda1a87 blob 52177 33735 700925 1 59add8b7ff14a8c06802bada413b896073c3456d
4ddc5876bce1eae1582d27f28dcc485bc161f86d4 blob 101645 65712 734660 1 59add8b7ff14a8c06802bada413b896073c3456d
565ae53938f211e46171b91a99c7eae81abea8125 blob 52141 33712 800372 2 ddc5876bce1eae1582d27f28dcc485bc161f86d4
66eb120431d740a2002715bc51e776a7bd9204a16 blob 52176 33742 834084 2 ddc5876bce1eae1582d27f28dcc485bc161f86d4
7ca30e55f268aa7d0a1c5b43516f4176affecb854 blob 52156 33718 867826 1 59add8b7ff14a8c06802bada413b896073c3456d
8non delta: 1 object
9chain length = 1: 4 objects
10chain length = 2: 2 objects
11.git/objects/pack/pack-f0b54d07f7fb8c2697c47bddd09d8df90f16b033.pack: okYou can see right away that it’s not the optimum because there are only two objects (instead of four) with chain length 2.
The uncompressed size of the deltas plus the base object is 1411032 ~= 104% times the optimum.
1$ git verify-pack -v .git/objects/pack/pack-*.idx | sed '/non delta:/Q' | awk '{ sum += $3 } END { print sum }'
21411032Oddly, if you don’t give the files random filenames (as i did), you get a much worse result (and git gc --aggressive doesn’t change anything).
$ git verify-pack -v .git/objects/pack/pack-*.idx | sed '/non delta:/Q' | awk '{ sum += $3 } END { print sum }'
1602091Update: here’s the optimal packfile:
git verify-pack -v .git/objects/pack/pack-*.idx
47649b95538818d51d1e926fe16b0950b7d34e75 blob 1048576 667173 12
ddc5876bce1eae1582d27f28dcc485bc161f86d4 blob 52187 33760 667185 1 47649b95538818d51d1e926fe16b0950b7d34e75
59add8b7ff14a8c06802bada413b896073c3456d blob 52184 33785 700945 1 47649b95538818d51d1e926fe16b0950b7d34e75
65ae53938f211e46171b91a99c7eae81abea8125 blob 52179 33770 734730 2 ddc5876bce1eae1582d27f28dcc485bc161f86d4
6eb120431d740a2002715bc51e776a7bd9204a16 blob 52196 33786 768500 2 ddc5876bce1eae1582d27f28dcc485bc161f86d4
613c0f78b0ec58462d9d4cf3f4c81b118dda1a87 blob 52192 33771 802286 2 59add8b7ff14a8c06802bada413b896073c3456d
ca30e55f268aa7d0a1c5b43516f4176affecb854 blob 52186 33771 836057 2 59add8b7ff14a8c06802bada413b896073c3456d
non delta: 1 object
chain length = 1: 2 objects
chain length = 2: 4 objects
.git/objects/pack/pack-2f13f76bab536f398326f02e03bb1906577f3dd8.pack: ok1$ git verify-pack -v .git/objects/pack/pack-*.idx | sed '/non delta:/Q' | awk '{ sum += $3 } END { print sum }'
21361700